
در یادگیری ماشینی، تکنیکهای مختلفی برای ساخت مدلها وجود دارد.
یکی از آنها یادگیری جمعی است که از ترکیبی از مدلها برای دستیابی به عملکرد بهتر استفاده میکند.
با تجمیع پیشبینیهای مختلف، مدلهای مجموعه میتوانند نتایج بهتری نسبت به جایگزینهای خود نشان دهند.
تصور کنید در حال تماشای یک مسابقه فوتبال هستید.
تحلیلگران ورزشی آمار دقیق و نظرات کارشناسی را در اختیار شما قرار میدهند.
همچنین نظرات دوستان علاقهمندی را که ممکن است شاهد مسابقات قبلی بودهاند نیز ارائه میدهند.
در هر دو مورد، قدرت دانش جمعی و دیدگاههای متعدد برای پیشبینیهای آگاهانهتر و قابل اعتمادتر، غلبه بر محدودیتهای تکیه صرفاً بر یک مدل، به کار گرفته میشود.
در این مقاله، در مورد نحوه عملکرد یادگیری جمعی صحبت خواهیم کرد، انواع مختلف الگوریتمهای یادگیری جمعی را بررسی خواهیم کرد و با مزایا و معایب یادگیری جمعی برای کارهای مختلف آشنا خواهیم شد.
1# یادگیری جمعی چیست؟
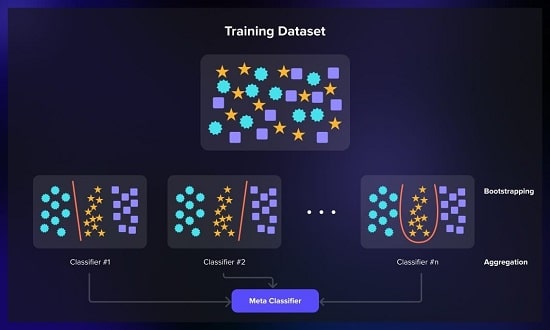
یادگیری جمعی یک رویکرد فرایادگیری است که از نقاط قوت مدلهای فردی مختلف که به عنوان یادگیرندگان پایه نیز شناخته میشوند، برای ایجاد یک مدل پیشبینی قویتر و دقیقتر استفاده میکند.
این مانند مشورت با تیمی از متخصصان است که هر کدام نقاط قوت و ضعف خود را در یک زمینه دارند تا به درک جامعی دست یابید و تصمیم آگاهانهتری بگیرید.
الگوریتمهای یادگیری جمعی، مدلهای متنوعی را بر روی مجموعههای داده یکسان آموزش میدهند و سپس نتایج آنها را برای پیشبینی نهایی دقیقتر ترکیب میکنند.
اصل اساسی این است که چندین مدل یادگیری ضعیف هنگامی که به صورت استراتژیک ترکیب شوند، میتوانند یک پیشبینی قویتر و قابلاعتمادتر را تشکیل دهند.
فرضیه کلیدی این است که مدلهای مختلف خطاهای نامرتبط خواهند داشت.
هنگامی که پیشبینیهای چند مدل به صورت هوشمند جمعآوری میشوند، خطاها لغو میشوند درحالی که پیشبینیهای صحیح تقویت میشوند.
2# روش کار در یادگیری جمعی
برای کارکرد یادگیری جمعی، باید از مدلهای متنوعی استفاده کنید.
اگر همه مدلهای مجموعه مشابه باشند، احتمالاً خطاهای مشابهی خواهند داشت.
مدلهای مختلف جنبههای متفاوتی از الگوهای دادههای زیربنایی را ثبت میکنند و خطاهای آنها منطبق نیستند.
به این ترتیب، در صورت ترکیب، نقاط قوت یک مدل میتوانند نقاط ضعف مدل دیگر را جبران کنند.
مدلهای یادگیری جمعی برای تعیین نتیجه کلی رأیگیری انجام میدهند.
دو استراتژی رأیگیری وجود دارد:
- رأی گیری سخت: در رأیگیری سخت، هر مدل در گروه یک پیشبینی انجام میدهد و پیشبینی نهایی با اکثریت آرا تعیین میشود.
- رای گیری نرم: در رأیگیری نرم، هر مدل در گروه یک تخمین احتمال برای هر کلاس ارائه میدهد.
سپس پیشبینی نهایی بر اساس میانگین این احتمالات یا مقادیر است.
رأیگیری سخت معمولاً برای پیشبینی برچسبهای کلاس استفاده میشود.
رأیگیری نرم زمانی میتواند اعمال شود که مدلهای پایه تخمینهای احتمال یا امتیازات اطمینان را ارائه میدهند.
3# تکنیکهای یادگیری جمعی
در یادگیری جمعی، تکنیکهای متعددی وجود دارد که میتوان برای موارد مختلف از آن ها استفاده کرد.
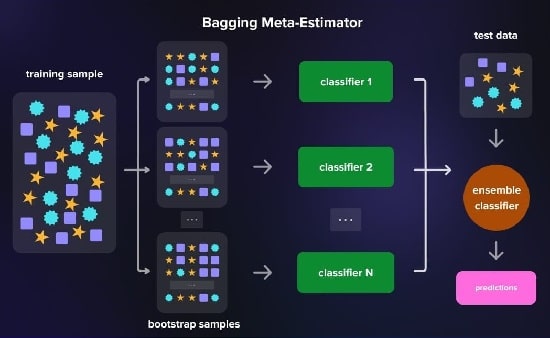
1-3# بستهبندی (تجمیع بوت استرپ)

بستهبندی (Bagging) شامل آموزش چندین نمونه از الگوریتم یادگیری یکسان در زیر مجموعههای مختلف دادههای آموزشی است.
مجموعهداده به نمونههای کوچکتر تقسیم میشود و سپس هر مدل در معرض یک نمونه تصادفی از مجموعهدادهها قرار میگیرد و پیش بینیها برای تولید خروجی نهایی به طور میانگین محاسبه میشوند.
تصور کنید که یک مجموعه داده بزرگ دارید که آن را به بخشهای کوچکتر تقسیم میکنید و همزمان به چندین مدل مشابه تغذیه میکنید.
هر مدل خروجی خاصی تولید میکند که یا برای وظایف طبقهبندی رأی داده میشود یا به عنوان میانگین برای رگرسیون محاسبه میشود.
بستهبندی زمانی مفید است که مدلی با واریانس بالا دارید و میخواهید بیش از حد نصب را کاهش دهید.
از جمله:
- مدلهای مبتنی بر درخت تصمیم در دادههای با ابعاد بالا مانند جنگل تصادفی برای طبقهبندی یا رگرسیون
- مجموعهای از شبکههای عصبی برای طبقهبندی تصاویر
2-3# تقویت
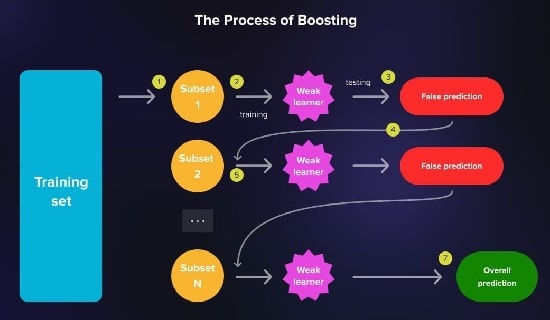
تقویت (Boosting) بر بهبود عملکرد یک یادگیرنده ضعیف در طول تکرار تمرکز دارد.
یادگیرندگان ضعیف مدلهایی هستند که عملکرد کمی بهتر از شانس تصادفی دارند.
برای بهبود عملکرد خود، مهندسان ماشین لرنینگ میتوانند از الگوریتمهایی مانند AdaBoost و Gradient Boosting استفاده کنند که در آن هر مدل به طور متوالی آموزش داده میشود.
در طول آموزش، زیر مجموعهای از دادههای آموزشی به مدل وارد میشود.
مدل پیشبینیهای نادرستی ارائه میدهد.
سپس نمونه به یک یادگیرنده ضعیف دیگر داده میشود و این فرایند برای چندین تکرار دیگر تکرار میگردد.
سپس مدل پیشبینی کلی را بر اساس تکرارهای قبلی خروجی میدهد.
تأکید بر اصلاح خطاهای انجام شده در مراحل قبلی است.
پیشبینی نهایی مجموع وزنی از پیشبینیهای فردی است که در آن مدلهایی که عملکرد خوبی دارند وزن بیشتری دارند.
تقویت زمانی استفاده میشود که شما یک مدل پایه ضعیف دارید و میخواهید آن را به یک مدل قوی تبدیل کنید.
از جمله این موارد عبارتاند از:
- مشکلات طبقهبندی که در آن هدف بهبود دقت است، مانند کشف تقلب یا فیلتر کردن هرزنامه.
- مشکلات رگرسیونی که در آن شما میخواهید یک متغیر پیوسته مانند پیشبینی قیمت مسکن را پیشبینی کنید.
3-3# انباشته شدن
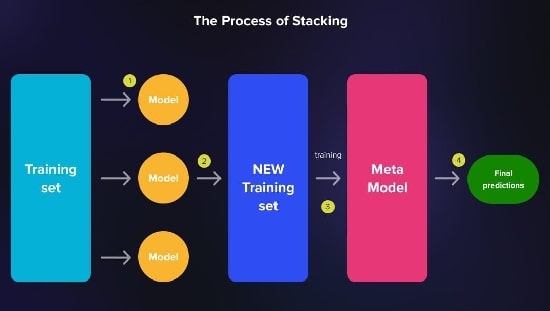
انباشته شدن (Stacking) از یک فرا آموز استفاده میکند و مدل دیگری است که خروجیهای مدلهای پایه را به عنوان ورودی میگیرد.
این روش معمولاً زمانی مورد استفاده قرار میگیرد که مدلهای مختلف در گروه، مهارتهای متفاوتی داشته باشند و خطاهای آنها به هم مرتبط نباشد.
سپس فرا آموز پیشبینی نهایی را بر اساس این خروجیهای ترکیبی انجام میدهد.
انباشتگی زمانی مؤثر است که مدلهای پایه مختلف در گرفتن جنبههای مختلف الگوهای دادههای اساسی تخصص داشته باشند.
انباشت زمانی استفاده میشود که میخواهید پیشبینیهای چند مدل را ترکیب کنید، نقاط قوت مدلهای فردی را به تصویر بکشید و عملکرد کلی را بهبود بخشید.
نمونه این موارد عبارتاند از:
- هر مشکل پیچیدهای که در آن انواع مختلف مدلها ممکن است در جنبههای مختلف مانند ترکیب یک مدل درخت تصمیم با یک شبکه عصبی برای مجموعهای متنوع از ویژگیها برتری داشته باشند.
- وظایف چندوجهی که در آن مدلهای مختلف انواع مختلفی از دادهها (متن، تصاویر و غیره) را مدیریت میکنند.
4# انواع الگوریتمهای یادگیری جمعی
یادگیری جمعی اغلب برای کارهای طبقهبندی و رگرسیون استفاده میشود؛ ولی برای هر کار، الگوریتمهای زیادی بسته به نوع مسئله، اندازه مجموعه دادهها و مبادلات موردنظر بین تفسیرپذیری، سرعت و دقت وجود دارند.
از جمله الگوریتمهای متداول میتوان موارد زیر را یاد کرد:
1-4# جنگل تصادفی
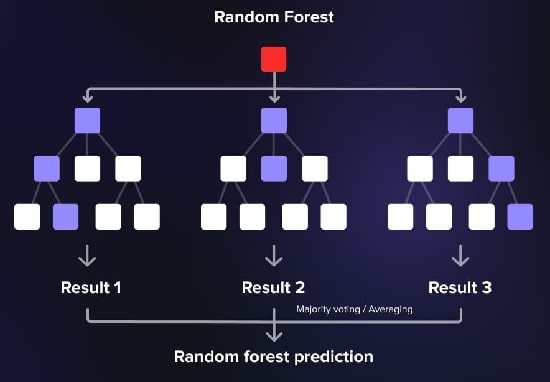
جنگل تصادفی چندین درخت تصمیم را در طول آموزش میسازد و پیشبینیهای آنها را ادغام میکند.
هر درخت بر روی یک زیر مجموعه تصادفی از دادههای آموزشی آموزش داده میشود و پیشبینی نهایی با اکثریت آرا تعیین میشود.
میتوان از آن برای طبقهبندی، رگرسیون و کارهای دیگر استفاده کرد.
2-4# تقویت تطبیقی (Adaptive Boost)

تقویت تطبیقی، وزنهایی را به نمونههای طبقهبندی اشتباه اختصاص میدهد و بر آموزش مدلهای بعدی برای اصلاح این خطاها تمرکز میکند.
پیشبینی نهایی مجموع وزنی از پیشبینیهای مدل فردی است.
این تکنیک برای حل مشکل زبانآموزان ضعیف برای مشکلات رگرسیون استفاده میشود.
3-4# افزایش گرادیان
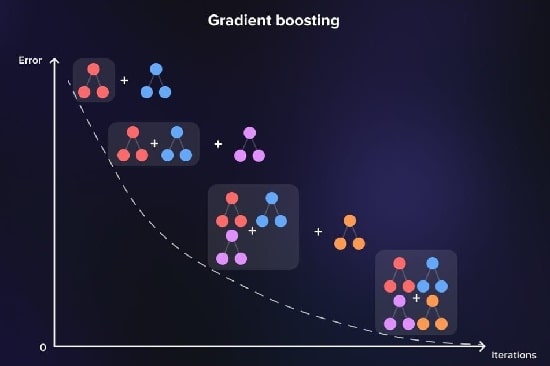
افزایش گرادیان درختها را به طور متوالی میسازد و هر درخت خطاهای درخت قبلی را تصحیح میکند.
برای یافتن وزنهای بهینه برای هر درخت، تابع تلفات را اغلب با استفاده از شیب نزول به حداقل میرساند.
این تکنیک همچنین برای حل مشکل یادگیرندگان ضعیف و برای کارهای رگرسیون و طبقهبندی استفاده میشود.
4-4# بستهبندی متا
BaggingClassifier و BaggingRegressor یک چارچوب کلی برای بستهبندی ارائه میدهند.
آنها را میتوان با طبقهبندی کنندههای پایه یا رگرسیونهای مختلف استفاده کرد.
5-4# کلاسبندی بر اساس آرا

کلاسبندی بر اساس آرا اجازه میدهد تا چندین طبقهبندیکننده را با رأی اکثریت ترکیب کنید.
این تکنیک از استراتژیهای رأیگیری نرم و سخت پشتیبانی میکند.
6-4# StackingClassifier و StackingRegressor
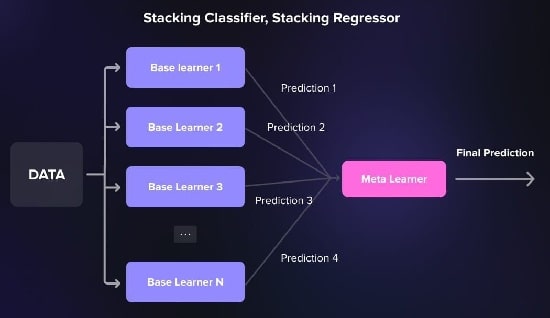
این دو الگوریتم، انباشتگی را با چند زبانآموز پایه و فرا آموز امکانپذیر میکنند.
آنها روشی منعطف برای آزمایش انباشتن در یک رابط سازگار با یادگیری scikit ارائه میدهند.
7-4# شبکههای عصبی

شبکههای عصبی را میتوان در یک مجموعه نیز استفاده کرد.
شما میتوانید از بستهبندی استفاده کنید و چندین شبکه را به طور مستقل آموزش دهید و پیشبینیهای آنها را ترکیب کنید.
5# مزایای یادگیری جمعی
1-5# دقت و پایداری بهبودیافته
روشهای یادگیری جمعی، نقاط قوت مدلهای فردی را با استفاده از دیدگاههای متنوع آنها در دادهها ترکیب میکنند.
هر مدل ممکن است در جنبههای مختلف، مانند گرفتن الگوهای مختلف یا مدیریت انواع خاصی از نویز، برتر باشد.
با ترکیب پیشبینیهای آنها از طریق رأیگیری یا میانگینگیری وزنی، روشهای جمعی میتوانند با گرفتن درک جامعتری از دادهها، دقت کلی را بهبود بخشند.
این به کاهش ضعفها و سوگیریهایی که ممکن است در هر مدل واحدی وجود داشته باشد، کمک میکند.
یادگیری جمعی که دقت مدل را در مدل طبقهبندی بهبود میبخشد درحالی که میانگین خطای مطلق را در مدل رگرسیون کاهش میدهد، میتواند یک مدل پایدار را کمتر مستعد برازش بیش از حد کند.
روشهای مجموعه همچنین مزیت مدیریت کارآمد مجموعهدادههای بزرگ را دارند که آنها را برای کاربردهای کلانداده مناسب میسازد.
علاوه بر این، روشهای یادگیری جمعی راهی برای ترکیب دیدگاهها و تخصصهای متنوع از مدلهای متعدد فراهم میکنند که منجر به پیشبینیهای قویتر میشود.
2-5# استحکام
یادگیری جمعی با درنظرگرفتن نظرات چندین مدل و انجام پیشبینیهای مبتنی بر اجماع، استحکام را افزایش میدهد.
این امر تأثیر نقاط دورافتاده یا خطاها را در یک مدل کاهش میدهد و نتایج دقیقتری را تضمین میکند.
ترکیب مدلهای متنوع، خطر سوگیری یا عدم دقت مدلهای فردی را کاهش میدهد و قابلیت اطمینان و عملکرد کلی رویکرد یادگیری جمعی را افزایش میدهد.
با این حال، ترکیب چندین مدل میتواند پیچیدگی محاسباتی را در مقایسه با استفاده از یک مدل افزایش دهد.
3-5# کاهش برازش بیش از حد
یادگیری جمعی با استفاده از زیر مجموعههای داده تصادفی برای آموزش هر مدل، اضافه برازش را کاهش میدهد.
انباشت، کیسه زنی تصادفی و تنوع را معرفی میکند و عملکرد تعمیم را بهبود میبخشد.
با تمرکز بر موارد چالشبرانگیز و بهبود دقت، وزنهای بالاتری را به نمونههایی که طبقهبندی آنها دشوار است، اختصاص میدهد.
تنظیم مکرر وزنها به یادگیری از اشتباهات و ساخت مدلها بهصورت متوالی کمک میکند.
6# چالشها در یادگیری جمعی

1-6# انتخاب مدل و وزندهی
انتخاب ترکیب مناسب از مدلها برای گنجاندن در مجموعه، تعیین وزن بهینه پیشبینیهای هر مدل و مدیریت منابع محاسباتی موردنیاز برای آموزش و ارزیابی چندین مدل به طور همزمان با سختی همراه است.
علاوه بر این، اگر مدلهای فردی بیش از حد مشابه باشند یا اگر دادههای آموزشی دارای نویز بالایی باشند، یادگیری مجموعه ممکن است همیشه عملکرد را بهبود نبخشد.
تنوع مدلها برای پوشش طیف گستردهتری از الگوهای داده حیاتی است.
وزندهی بهینه سهم هر مدل، اغلب بر اساس معیارهای عملکرد، برای مهار قدرت پیشبینی جمعی آنها بسیار مهم است؛ بنابراین، بررسی و آزمایش دقیق برای دستیابی به نتایج مطلوب با یادگیری جمعی ضروری است.
2-6# پیچیدگی محاسباتی
یادگیری جمعی، شامل چندین الگوریتم و مجموعه ویژگیها، به منابع محاسباتی بیشتری نسبت به مدلهای فردی نیاز دارد.
در حالی که پردازش موازی راهحلی ساده را ارائه میدهد، سازماندهی مجموعهای از مدلها در چندین پردازنده میتواند پیچیدگی را هم در اجرا و هم در نگهداری ایجاد کند.
همچنین، محاسبات بیشتر ممکن است همیشه منجر به عملکرد بهتر نشود، به خصوص اگر مجموعه بهدرستی تنظیم نشده باشد یا اگر مدلها خطاهای یکدیگر را در مجموعهدادههای پر سروصدا تقویت کنند.
3-6# تنوع و تطبیق بیش از حد
یادگیری جمعی به مدلهای متنوعی برای جلوگیری از تعصب و افزایش دقت نیاز دارد.
با ترکیب الگوریتمها، مجموعههای ویژگیها و دادههای آموزشی مختلف، یادگیری جمعی:
- طیف وسیعتری از الگوها را به تصویر میکشد.
- خطر بیش از حد برازش را کاهش میدهد.
- اطمینان میدهد که گروه میتواند سناریوهای مختلف را مدیریت کند.
- پیشبینیهای دقیق در زمینههای مختلف انجام دهد.
که برای این کار باید تطبیقهای زیادی صورت پذیرد.
4-6# تفسیرپذیری
مدلهای یادگیری گروهی، دقت را بر تفسیرپذیری اولویت میدهند که منجر به پیشبینیهای بسیار دقیق میشود.
با این حال، این مبادله، تفسیر مدل مجموعه را چالشبرانگیزتر میکند.
تکنیکهایی مانند تجزیهوتحلیل اهمیت ویژگی و دروننگری مدل میتواند به ارائه بینش کمک کند؛ اما ممکن است به طور کامل پیشبینی مجموعههای پیچیده را ابهام کند.
7# کاربردهای دنیای واقعی یادگیری جمعی
یادگیری جمعی در دنیای تحقیقاتی کاربردهای فراوانی دارد؛ اما از کاربردهای آن در دنیای واقعی میتوان موارد زیر را یاد کرد:
1-7# مراقبتهای بهداشتی
یادگیری جمعی در مراقبتهای بهداشتی برای تشخیص بیماری و کشف دارو استفاده میشود.
این پیشبینیها را از چندین مدل یادگیری ماشینی که بر روی ویژگیها و الگوریتمهای مختلف آموزش دیدهاند، ترکیب میکند و تشخیصهای دقیقتری ارائه میدهد.
روشهای مجموعه همچنین دقت طبقهبندی را بهبود میبخشند، بهویژه در مجموعه دادههای پیچیده یا زمانی که مدلها دارای نقاط قوت و ضعف مکمل هستند.
طبقهبندیکنندههای جمعی مانند جنگلهای تصادفی در مراقبتهای بهداشتی برای دستیابی به عملکرد بالاتر نسبت به مدلهای فردی استفاده میشوند و دقت این وظایف را افزایش میدهند.
2-7# کشاورزی
مدلهای یادگیری گروهی، چندین مدل پایه را ترکیب میکنند تا نقاط دورافتاده و نویز را کاهش دهند که منجر به پیشبینی دقیقتر میشوند.
این بهویژه در پیشبینی فروش، تجزیهوتحلیل بازار سهام و پیشبینی آبوهوا مفید است.
در کشاورزی، یادگیری جمعی را میتوان برای پیشبینی عملکرد محصول به کار برد.
ترکیب پیشبینیهای چند مدل آموزشدیده بر روی عوامل محیطی مختلف، مانند دما، بارندگی و کیفیت خاک، میتوانند پیشبینی دقیقتری از عملکرد محصول ارائه دهند.
تکنیکهای یادگیری گروهی، عملیاتی مانند چیدن و بستهبندی، عملکرد و قابلیت اطمینان را بهبود میبخشد.
3-7# بیمه
شرکتهای بیمه همچنین میتوانند از روشهای مجموعهای در ارزیابی ریسک و تعیین حق بیمه بهرهمند شوند.
شرکتهای بیمه با ترکیب پیشبینیهای چند مدل آموزشدیده بر روی عوامل مختلف مانند جمعیتشناسی، دادههای تاریخی و روند بازار، میتوانند ریسکهای بالقوه را بهتر درک کنند و پیشبینیهای دقیقتری از احتمالات خسارت انجام دهند.
این میتواند به آنها کمک کند تا حق بیمه مناسبی را برای مشتریان خود تعیین کنند و از کسبوکار بیمه عادلانه و پایدار اطمینان حاصل کنند.
4-7# سنجش از دور

تکنیکهای یادگیری جمعی، مانند جنگلهای جداسازی، ناهنجاریهای دادهها را با مقایسه خروجیهای مدلهای متعدد تشخیص میدهند.
آنها دقت تشخیص را افزایش داده و موارد مثبت کاذب را کاهش میدهند و آنها را برای شناسایی تراکنشهای تقلبی، نفوذ به شبکه یا رفتار غیرمنتظره مفید میکنند.
این روشها را میتوان در سنجشازدور با ترکیب مدلها یا الگوریتمهای متعدد، آموزش بر روی زیرمجموعههای مختلف داده و ترکیب پیشبینیها از طریق رأی اکثریت یا میانگینگیری وزنی به کار برد.
5-7# ورزش
یادگیری جمعی در ورزش شامل استفاده از مدلها یا الگوریتمهای پیشبینی چندگانه برای پیشبینیها و تصمیمگیریهای دقیقتر در جنبههای مختلف صنعت ورزش است.
روشهای متداول مجموعه شامل چیدمان مدل و میانگینگیری وزنی است که دقت و اثربخشی سیستمهای توصیه را بهبود میبخشد.
با ترکیب پیشبینیهای مدلهای مختلف، مانند الگوریتمهای یادگیری ماشین یا مدلهای آماری، یادگیری جمعی به تیمهای ورزشی، مربیان و تحلیلگران کمک میکند تا درک بهتری از عملکرد بازیکن، نتایج بازی و تصمیمگیری استراتژیک به دست آورند.
این رویکرد همچنین میتواند در زمینههای ورزشی دیگر مانند پیشبینی آسیب، استعدادیابی و استراتژیهای تعامل با طرفداران نیز اعمال شود.
سخن آخر
یادگیری جمعی یک تکنیک یادگیری ماشینی است که عملکرد مدلهای یادگیری ماشین را با ترکیب پیشبینیهای چند مدل بهبود میبخشد.
هدف روشهای مجموعه، کاهش سوگیری و واریانس با استفاده از نقاط قوت الگوریتمهای متنوع است که منجر به پیشبینیهای قابلاعتمادتر میشود.
این تکنیکها همچنین استحکام مدل را در برابر خطاها و عدم قطعیتها، بهویژه در کاربردهای حیاتی مانند مراقبتهای بهداشتی یا مالی افزایش میدهد و با بهبود عملکرد، قابلیت اطمینان را افزایش میدهد و برای تیمهایی که میخواهند سیستمهای ML قابل اعتماد بسازند، ارزشمند هستند.
ثابت شده است که تکنیکهای یادگیری گروهی عملکرد بهتری در مشکلات یادگیری ماشین دارند.
ما میتوانیم از این تکنیکها برای رگرسیون و همچنین مشکلات طبقهبندی استفاده کنیم.
پیشبینی نهایی از این تکنیکهای ترکیبی با ترکیب نتایج چندین مدل پایه به دست میآید.
میانگینگیری، رأیگیری و پشتهبندی برخی از روشهایی هستند که نتایج برای بهدست آوردن یک پیشبینی نهایی در آنها ترکیب میشوند.
درباره نویسنده : معصومه آذری
نظرتون درباره این مقاله چیه؟
ما رو راهنمایی کنید تا اون رو کامل تر کنیم و نواقصش رو رفع کنیم.
توی بخش دیدگاه ها منتظر پیشنهادهای فوق العاده شما هستیم.
