
کیفیت دادهها کلید موفقیت هر سازمانی است.
اگر دادههای خوبی ندارید، اساساً در حال پرواز کور هستید.
در این حالت، قبل از اینکه متوجه شوید، بهرهوری ضربه میزند، سیستمها از کار میافتند و هزینهها شروع به افزایش میکنند.
برای مبارزه با این مسائل و افزایش کیفیت دادههای خود، یکی از مؤثرترین استراتژیها، نرمال سازی داده است.
نرمال سازی دادهها یک فرایند همهکاره با هدف بهحداقل رساندن خطاها و ناسازگاریها در دادهها است که میتواند کارایی و دقت سیستمهای داده را به میزان قابل توجهی تضعیف کند.
این کار افزونگی را کاهش میدهد و دادهها را استاندارد میکند تا یکپارچگی و سازگاری را در زمینههای مختلف، از مدیریت پایگاه داده گرفته تا تجزیهوتحلیل دادهها و یادگیری ماشینی، ارتقا دهد.
در این راهنما، مفهوم پیچیده نرمالسازی دادهها را تجزیه میکنیم و انواع و کاربردهای آن را بررسی میکنیم تا به شما در مدیریت مؤثرتر دادهها کمک کنیم؛ اما ابتدا اجازه دهید با بحث در مورد ناهنجاریهای دادهها شروع کنیم.
1# ناهنجاریهای داده چیست؟

ناهنجاریهای داده به تناقضات یا خطاهایی اشاره دارد که هنگام برخورد با دادههای ذخیره شده، رخ میدهد.
این ناهنجاریها میتوانند یکپارچگی دادهها را به خطر بیندازند و باعث نادرستی شوند که سناریوی واقعی را که دادهها قرار است نشان دهند، منعکس نمیکنند.
صرف نظر از زمینه، ناهنجاریها میتوانند به طور قابل توجهی بر ثبات و یکپارچگی دادهها تأثیر بگذارند.
آنها میتوانند باعث تحلیلهای نادرست، نتایج گمراه کننده و تصمیمگیری ضعیف شوند؛ بنابراین، شناسایی و رسیدگی به ناهنجاریهای دادهها گامی مهم در هر فرایند مبتنی بر داده است.
2# انواع ناهنجاریهای دادهها و منشا آنها

ناهنجاریهای دادهها میتوانند از طیف وسیعی از منابع سرچشمه بگیرند و تأثیر آنها میتواند متفاوت باشد و اگر بهدرستی مورد توجه قرار نگیرد، اغلب باعث ایجاد عوارض اساسی میشود.
در اینجا ما در مورد 2 دسته کلی از ناهنجاریها که بیشترین شیوع را دارند، صحبت میکنیم.
1-2# ناهنجاریها در پایگاههای داده
وقتی صحبت از پایگاههای داده به میان میآید، 3 نوع اصلی ناهنجاری دادهها ناشی از عملیات بهروزرسانی، درج و حذف است:
- ناهنجاریهای درج: این موارد زمانی رخ میدهند که افزودن دادههای جدید به پایگاه داده به دلیل عدم وجود سایر دادههای ضروری مانع شود.
این وضعیت اغلب در سیستمهایی که وابستگیهای خاصی بین عناصر داده وجود دارد، ایجاد میشود. - ناهنجاریهای بهروزرسانی: این نوع ناهنجاریها، زمانی اتفاق میافتند که تغییرات در دادهها منجر به ناسازگاری میشود.
این معمولاً زمانی اتفاق میافتد که یک داده یکسان در چندین مکان ذخیره میشود و تغییرات به طور یکسان در همه موارد منعکس نمیشوند. - ناهنجاریهای حذف: زمانی با این ناهنجاریها مواجه میشوید که به طور ناخواسته اطلاعات ارزشمند دیگری را در حین حذف دادههای خاص از دست میدهید.
این معمولاً زمانی اتفاق میافتد که چندین بخش از اطلاعات با هم ذخیره میشوند و حذف یکی بر دیگری تأثیر میگذارد.
در حالی که ناهنجاریهای فوق عمدتاً به عملیات در پایگاهداده و نقصهای طراحی آنها مربوط میشود، بدانید که ناهنجاریها تنها به این جنبهها محدود نمیشوند.
آنها به خوبی میتوانند در خود دادهها وجود داشته باشند و میتوانند منبعی برای تجزیهوتحلیل و تفسیرهای گمراه کننده باشند.
2-2# ناهنجاری در تجزیهوتحلیل دادهها و یادگیری ماشین
در تجزیهوتحلیل دادهها و یادگیری ماشین، ناهنجاریهای دادهها میتوانند به صورت اختلاف در مقادیر، انواع یا کامل بودن دادهها ظاهر شوند که میتواند به طور قابل توجهی بر نتیجه تحلیلها یا مدلهای پیشبینی تأثیر بگذارد.
برخی از ناهنجاریهای کلیدی که در این زمینه رخ میدهند، به صورت زیر است:
- مقادیر ازدسترفته: زمانی اتفاق میافتد که دادهها برای مشاهدات یا متغیرهای خاصی در دسترس نباشد.
- انواع دادههای نادرست: این ناهنجاریها زمانی رخ میدهند که نوع داده یک متغیر با نوع داده مورد انتظار مطابقت نداشته باشد.
به عنوان مثال، یک متغیر عددی ممکن است به عنوان یک رشته ثبت شود. - مقادیر غیرواقعی: این نوع ناهنجاری زمانی به وجود میآید که متغیرها حاوی مقادیری باشند که از نظر فیزیکی ممکن یا واقعی نیستند.
به عنوان مثال، متغیری که سن انسان را نشان میدهد ممکن است دارای مقدار 200 باشد.
حال، بیایید به اصول نرمال سازی دادهها و اهمیت آن در مدیریت ناهنجاریهای داده نگاه کنیم.
این جنبه حیاتی از مدیریت و تجزیهوتحلیل دادهها، فرایند کارآمدتری را با استانداردسازی دادهها، حذف افزونگیها و رسیدگی به خطاهای ورودی نامطلوب تضمین میکند.
با کاهش تأثیر ناهنجاریها، نرمال سازی دادهها نقش مهمی در دستیابی به نتایج قابل اعتماد ایفا مینماید.
3# نرمال سازی داده چیست؟

نرمال سازی داده راهی برای سازماندهی و ساختاردهی اطلاعات در مجموعهداده است.
این فرایند به کاهش دادههای تکراری کمک کرده، ذخیرهسازی و بازیابی را کارآمدتر میکند.
هدف از نرمال سازی این است که با استاندارد کردن نحوه قالببندی و ساختار اطلاعات، موارد را ثابت نگه داریم و بینظمیهای داده را حذف کنیم.
در یک مجموعه داده نرمال شده، دادهها در واحدهای منظم قرار میگیرند و اتصالات بین این واحدها برای کاهش تکرار و اتکا به سایر دادهها تنظیم شده است.
این روش دقت دادهها را بهبود میبخشد، مدیریت آن را آسانتر میکند و امکان جستجو و تجزیهوتحلیل سریعتر و سادهتر را فراهم میکند.
4# کاربرد نرمال سازی داده
نرمال سازی دادهها در طیف گستردهای از زمینهها و حرفهها کاربرد دارد.
توانایی آن در سادهسازی و ذخیرهسازی دادهها، کاهش خطای ورودی دادهها و اطمینان از ثبات، آن را به یک دارایی ارزشمند برای هر کسی که با مجموعهدادههای بزرگ سروکار دارد، تبدیل میکند.
اجازه دهید در مورد برخی از موارد استفاده آن بحث کنیم.
1-4# نرمال سازی دادهها در یادگیری ماشینی
نرمال سازی دادهها یک مرحله پیشپردازش استاندارد در یادگیری ماشین است.
مهندسان یادگیری ماشین، از آن برای استانداردسازی و مقیاسبندی دادههای خود استفاده میکنند که برای اطمینان از اینکه هر ویژگی تأثیر یکسانی بر پیشبینی دارد، بسیار مهم است.
2-4# نرمال سازی دادهها در پژوهش
محققان، بهویژه آنهایی که در زمینه علوم و مهندسی هستند، اغلب از نرمال سازی دادهها در کار خود استفاده میکنند.
چه آنهایی که با دادههای تجربی سروکار دارند یا با مجموعهدادههای بزرگ کار میکنند، نرمال سازی به سادهسازی دادههای آنها کمک میکند و تجزیهوتحلیل و تفسیر آن را آسانتر مینماید.
آنها از آن برای حذف اعوجاجهای بالقوه ناشی از مقیاسها یا واحدهای مختلف استفاده مینمایند و اطمینان حاصل میکنند که یافتههای آنها دقیق و قابل اعتماد است.
3-4# نرمال سازی داده در تجارت
در دنیای تجارت، نرمال سازی داده اغلب در هوش تجاری و تصمیمگیری استفاده میشود.
تحلیلگران کسبوکار از نرمال سازی برای آمادهسازی دادهها برای تجزیهوتحلیل استفاده میکنند و به آنها در شناسایی روندها، انجام مقایسه و نتیجهگیری معنادار کمک مینمایند.
این به تصمیمگیریها و استراتژیهای کسبوکار آگاهانهتر برای هدایت رشد و موفقیت کمک میکند.
نرمال سازی همچنین سازگاری دادهها را بهبود میبخشد که منجر به همکاری بهتر بین تیمهای مختلف در شرکت میشود.
5# اهمیت نرمال سازی دادهها

نرمال سازی دادهها مهم است؛ زیرا در زمینههای مختلف از جمله آمار، تجزیهوتحلیل دادهها و یادگیری ماشین به ما کمک میکند.
این فرایند به دلایل زیر برای کسبوکارها اهمیت زیادی دارد:
1-5# تجزیهوتحلیل دادههای قابلاعتماد
نرمال سازی، دادههای منسجم و دقیق را تضمین میکند و پایهای محکم برای تجزیهوتحلیل دادهها فراهم مینماید.
این کار، کسبوکارها را قادر میسازد تا بینشهای معنیداری به دست آورند و بر اساس دادههای قابلاعتماد و ساختاریافته تصمیم آگاهانه بگیرند.
تجزیهوتحلیل انجام شده بر روی دادههای نرمال شده، منجر به نتایج دقیقتر و قابلاعتمادتر میشود و به سازمانها اجازه میدهد تا بینشها و الگوهای ارزشمندی را کشف کنند.
2-5# یکپارچهسازی دادهها
دادههای نرمال شده یکپارچهسازی با سایر سیستمها و برنامهها را تسهیل میکنند و باعث افزایش قابلیت همکاری میگردند و به کسبوکارها اجازه میدهند تا دادهها را به طور مؤثر در پلتفرمها و فرایندهای مختلف به اشتراک بگذارند.
علاوه بر این، هنگامی که دادهها بر اساس اصول استاندارد، سازماندهی میشوند، ادغام دادهها از منابع و سیستمهای مختلف آسانتر میشود که این، کسبوکارها را قادر میسازد تا از پتانسیل کامل اکوسیستم داده خود استفاده کنند.
3-5# مقیاسپذیری و انعطافپذیری
ساختارهای داده نرمال شده انعطافپذیر و سازگار با نیازهای در حال تحول کسبوکار هستند.
همانطور که سازمانها رشد میکنند، نرمال سازی آنها را قادر میسازد تا به راحتی پایگاهدادههای خود را بدون به خطر انداختن یکپارچگی دادهها گسترش دهند و اصلاح کنند.
با دادههای نرمالشده، کسبوکارها میتوانند نیازهای دادههای جدید را تطبیق دهند و ساختار مجموعه داده خود را با تکامل عملیاتشان در طول زمان تنظیم نمایند.
6# روش انجام نرمال سازی داده
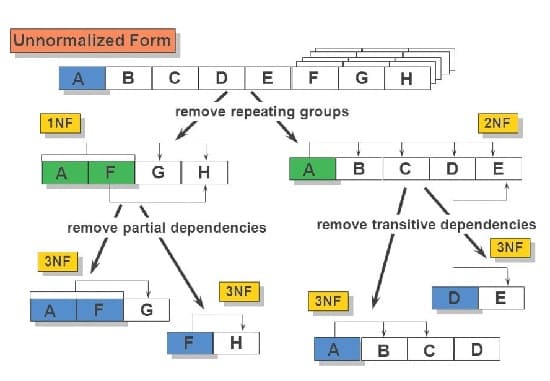
اصولاً فرایند نرمال سازی در دادههای مختلف، تکنیکهای متفاوتی دارد.
در اینجا تکنیکهای دو مورد اصلی از دادهها، پایگاهداده و یادگیری ماشین را به دلیل کاربرد فراوان مورد بررسی قرار میدهیم:
1-6# نرمال سازی دادهها در پایگاههای داده
نرمال سازی دادهها در پایگاههای داده یک فرایند چند مرحلهای است که شامل اعمال یک سری قوانین به نام “فرم نرمال” میشود.
هر فرمی، سطحی از نرمال سازی را نشان میدهد و مجموعهای از شرایط خاص خود را دارد که پایگاه داده باید رعایت کند.
این فرمهای نرمال مجموعهای از قوانین را ارائه میدهند که پایگاهداده برای دستیابی به سطح معینی از نرمالسازی باید به آنها پایبند باشد.
این فرایند با اولین فرم نرمال (1NF) شروع میشود و میتواند تا پنجمین فرم نرمال (5NF) پیش برود که هر سطح به نوع خاصی از افزونگی یا ناهنجاری داده میپردازد.
بیایید نگاهی به هر یک از آنها بیندازیم.
1) اولین فرم نرمال (1NF)
اولین فرم نرمال (1NF) مرحله اولیه نرمال سازی دادهها است.
اگر یک پایگاهداده دارای مقادیر اتمی باشد در 1NF است.
این بدان معنی است که هر سلول در پایگاهداده دارای یک مقدار واحد است و هر رکورد منحصربهفرد است.
این مرحله دادههای تکراری را حذف میکند و تضمین میکند که هر ورودی در پایگاهداده دارای یک شناسه منحصربهفرد است که سازگاری دادهها را افزایش میدهد.
2) فرم نرمال دوم (2NF)
یک پایگاه داده در صورتی به دومین شکل نرمال (2NF) میرسد که قبلاً در 1NF باشد و همه ویژگیهای غیرکلیدی، کاملاً از نظر عملکردی به کلید اصلی وابسته باشند.
به عبارت دیگر، هیچ وابستگی جزئی در پایگاهداده نباید وجود داشته باشد.
این مرحله افزونگی را بیشتر کاهش میدهد و تضمین میکند که هر قطعه داده در پایگاهداده با کلید اصلی مرتبط است که به طور منحصربهفرد هر رکورد را شناسایی میکند.
3) فرم سوم نرمال (3NF)
سومین شکل نرمال (3NF) در صورتی به دست میآید که پایگاهداده در 2NF باشد و هیچ وابستگی گذرایی وجود نداشته باشد.
این بدان معنی است که هیچ ویژگی کلید غیراصولی نباید به ویژگی کلید غیر اولیه دیگری وابسته باشد.
این مرحله تضمین میکند که هر ویژگی غیرکلیدی جدول به طور مستقیم به کلید اصلی و نه به سایر ویژگیهای غیرکلیدی وابسته است.
4) فراتر از 3NF
درحالیکه اکثر پایگاههای داده پس از رسیدن به 3NF نرمال شده در نظر گرفته میشوند، مراحل دیگری از نرمال سازی وجود دارد، از جمله فرم چهارم نرمال (4NF) و پنجمین فرم نرمال (5NF).
این مراحل با انواع پیچیدهتری از وابستگیهای داده سروکار دارند و هنگام برخورد با مجموعهدادههای پیچیدهتر استفاده میشوند.
با این حال، در بیشتر موارد، اطمینان از یکپارچگی و کارایی داده در سطح 3NF از قبل کافی است.
2-6# نرمال سازی دادهها در تجزیهوتحلیل دادهها و یادگیری ماشینی

در تجزیهوتحلیل دادهها و گردش کار یادگیری ماشین، نرمال سازی دادهها یک مرحله پیشپردازش است.
مقیاس دادهها را تنظیم میکند و اطمینان میدهد که همه متغیرهای یک مجموعه داده در مقیاس مشابهی هستند.
این یکنواختی مهم است؛ زیرا از تحتالشعاع قرار دادن هر متغیری بر سایر متغیرها جلوگیری میکند.
برای الگوریتمهای یادگیری ماشینی که به روشهای مبتنی بر فاصله یا گرادیان متکی هستند، دادههای نرمالشده بهویژه کلیدی است.
نرمالسازی به این الگوریتمها کمک میکند تا عملکرد بهینه داشته باشند و منجر به ایجاد مدلهایی میشود که دقیق، قابل اعتماد و بیطرف باشند و در نهایت کیفیت بینشهای بهدستآمده از دادهها را افزایش میدهد.
چندین تکنیک نرمالسازی مختلف وجود دارد که میتواند در دادهکاوی استفاده شود، از جمله:
1) نرمال سازی Min-Max
این تکنیک مقادیر یک ویژگی را در محدودهای بین 0 و 1 مقیاس میکند.
این کار با کم کردن مقدار حداقل ویژگی از هر مقدار و سپس تقسیم بر دامنه ویژگی انجام میشود.
2) نرمال سازی امتیاز Z
این تکنیک مقادیر یک ویژگی را برای داشتن میانگین 0 و انحراف استاندارد 1 مقیاس میکند.
این کار با کم کردن میانگین ویژگی از هر مقدار و سپس تقسیم بر انحراف استاندارد انجام میشود.
3) مقیاسدهی
این تکنیک مقادیر یک ویژگی را با تقسیم مقادیر یک ویژگی بر توان 10 مقیاس میکند.
4) تبدیل لگاریتمی
این تکنیک یک تبدیل لگاریتمی را برای مقادیر یک ویژگی اعمال میکند.
این میتواند برای دادههایی با طیف وسیعی از مقادیر مفید باشد؛ زیرا میتواند به کاهش تأثیر داده پرت کمک کند.
5) تبدیل ریشه
این تکنیک یک تبدیل ریشه مربع را برای مقادیر یک ویژگی اعمال میکند.
این میتواند برای دادههایی با طیف وسیعی از مقادیر مفید باشد؛ زیرا میتواند به کاهش تأثیر مقادیر پرت کمک کند.
توجه به این نکته مهم است که نرمالسازی باید فقط برای ویژگیهای ورودی نه متغیر هدف، اعمال شود.
تکنیکهای نرمالسازی متفاوت ممکن است برای انواع مختلف دادهها و مدلها بهتر عمل کند.
7# مزایای نرمال سازی داده

نرمال سازی دادهها مزایای متعددی را ارائه میدهد.
از جمله مزایای نرمال سازی داده میتوان به موارد زیر اشاره کرد:
1-7# بهبود سازماندهی کلی مجموعهداده
پس از نرمال سازی، مجموعهداده شما بهگونهای ساختاریافته و مرتب میشود که برای تمام بخشها در سراسر شرکت منطقی باشد.
با افزایش سازماندهی، خطاهای تکراری و مکان به حداقل میرسد و نسخههای قدیمی دادهها میتوانند راحتتر بهروزرسانی شوند.
2-7# ثبات دادهها
دادههای ثابت برای همه تیمهای یک کسبوکار برای ماندن در یک صفحه بسیار مهم است.
نرمالسازی دادهها، سازگاری بین تیمهای توسعه، تحقیق و فروش را تضمین میکند.
دادههای ثابت همچنین گردش کار بین بخشها را بهبود میبخشد و مجموعههای اطلاعاتی آنها را تراز میکند.
3-7# کاهش افزونگی
افزونگی یک مشکل ذخیرهسازی داده است که معمولاً نادیده گرفته میشود.
کاهش افزونگی در نهایت به کاهش حجم فایل و در نتیجه سرعت بخشیدن به تجزیهوتحلیل و زمان پردازش دادهها کمک میکند.
4-7# کاهش هزینه
کاهش هزینه به دلیل نرمال سازی اوج مزایای ذکر شده قبلی است.
به عنوان مثال، اگر اندازه فایل کاهش یابد، ذخیرهسازی دادهها و پردازندهها نیازی به بزرگی ندارد.
علاوه بر این، افزایش گردش کار به دلیل سازگاری و سازماندهی، اطمینان حاصل میکند که همه کارکنان میتوانند در سریعترین زمان ممکن به داده دسترسی پیدا کنند و در زمان برای سایر وظایف ضروری صرفهجویی شود.
افزایش امنیت: ازآنجاییکه نرمالسازی مستلزم این است که دادهها با دقت بیشتری مکانیابی شوند و به طور یکنواخت سازماندهی شوند، امنیت به میزان قابلتوجهی افزایش مییابد.
8# چالشهای نرمال سازی دادهها

- پیچیدگی روابط: چالش اصلی در پرداختن به روابط پیچیده بین موجودیتهای داده است.
نرمال سازی ساختارهای داده پیچیده بدون به خطر انداختن روابط نیازمند بررسی و برنامهریزی دقیق است. - پیامدهای عملکرد: نرمال سازی دادهها میتواند بر عملکرد تأثیر بگذارد.
بهویژه زمانی که برای بازسازی دادههای نرمال شده به اتصالهای مکرر نیاز است.
این چالشهایی مانند افزایش پیچیدگی پرسوجو و زمان پردازش را معرفی میکند. - سازگاری در میان سیستمها: حفظ ثبات در سیستمها و پایگاههای اطلاعاتی متنوع یک چالش است.
این معمولاً در سازمانهای بزرگی اتفاق میافتد که نیاز به هماهنگی مؤثر برای اطمینان از نمایش یکنواخت دادهها دارند.
نتیجهگیری
از استارتآپهای کوچک گرفته تا شرکتهای بزرگ، بر کسی پوشیده نیست که دادهها به اولویت اصلی هر کسبوکاری تبدیل شده است.
همانطور که شرکتها دادهها را جمعآوری، ذخیره و تجزیهوتحلیل میکنند، مجموعهداده را برای مدیریت آنها میسازند و از آنها استفاده میکنند.
در این زمینه روبهرشد دادههای بزرگ، اصطلاحی به نام نرمال سازی داده مطرح شده است.
نرمال سازی دادهها یک فرایند ضروری برای شرکتهایی است که میخواهند ارزش دادههای خود را به حداکثر برسانند.
با استانداردسازی و سازماندهی دادهها، کسبوکارها میتوانند از تجزیهوتحلیل دقیقتر، عملکرد بهتر و یکپارچگی روانتر در بین سیستمها اطمینان حاصل کنند.
چه به دنبال بهبود مدلهای یادگیری ماشینی خود باشید و چه به دنبال سادهسازی فرایندهای مدیریت داده خود باشید، نرمالسازی یک گام کلیدی برای موفقیت است.
درباره نویسنده : معصومه آذری
نظرتون درباره این مقاله چیه؟
ما رو راهنمایی کنید تا اون رو کامل تر کنیم و نواقصش رو رفع کنیم.
توی بخش دیدگاه ها منتظر پیشنهادهای فوق العاده شما هستیم.
