
اگر یک دولوپر یا توسعه دهنده پایتون باشید که به دنبال ارتقای جعبه ابزار هوش مصنوعی خود هستید، پس یک بلیط طلایی برای توسعه راه حلهای یادگیری ماشینی به صورتی قدرتمند دارید.
استفاده از کتابخانه sci-kit learn بلیط برنده شما است.
این کتابخانه، فرآیندهایی مانند طبقه بندی، رگرسیون و خوشهبندی را بسیار سادهتر خواهد کرد.
زمانی که برای اولین بار از این کتابخانه استفاده میکنید، برای زمانی که قبلاً برای آماده سازی دادههای خود برای یادگیری ماشین صرف میکردید، حتماً غبطه خواهید خورد.
در این مقاله به بررسی کتابخانه sci-kit learn، مفاهیم اولیه آن، قابلیتهای آن، کاربردهای کتابخانه sci-kit learn، علل اهمیت آن، نحوه نصب، مزایا و معایب استفاده از این کتابخانه و چشم انداز آینده sci-kit learn خواهیم پرداخت.
1# کتابخانه sci-kit learn چیست؟

کتابخانه sci-kit learn، یک کتابخانه منبع باز است که با ارائه طیف گستردهای از ابزار به منظور یادگیری تحت نظارت و بدون نظارت، یادگیری ماشین را آسانتر و در دسترستر میکند.
با استفاده از این کتابخانه، انجام فرآیندهایی همچون تجزیه و تحلیل دادهها و مدلسازیهای پیش بینی به مراتب آسانتر خواهد شد.
یکی از بهترین ویژگیهای این کتابخانه، چگونگی ادغام یکپارچه آن با سایر استکهای (Stacks) علم داده در پایتون است.
این موضوع، هم افزایی عملکرد و سهولت استفاده از آن را افزایش میدهد.
در نتیجه به علت سادگی، کارایی و ادغام دقیق با موارد زیر به یک ابزار اساسی برای استفاده از یادگیری ماشین در پایتون تبدیل شده است:
- SciPy
- NumPy
- Matplotlib
رابط بصری و مستندات عالیای که در این کتابخانه وجود دارد، آن را به یک کتابخانه برای آموزش یادگیری ماشین و ابزاری قابل اعتماد به منظور استفاده از یادگیری ماشین برای حل مشکلات دنیای واقعی در صنایع و دانشگاهها مبدل ساخته است.
استحکام و انعطاف پذیری ای که این کتابخانه دارد، آن را در صنایع مختلف از امور مالی گرفته تا مراقبتهای بهداشتی ضروری کرده است.
تقاضای فزایندهای که برای هوش مصنوعی پیش بینی کننده و تصمیم گیریهای مبتنی بر داده وجود دارد، نقش حیاتی sci-kit learn را در تحول دیجیتال و همسویی استراتژیک کسب و کار برجسته کرده است.
بنابراین چه مبتدی باشید چه سینیور، این کتابخانه برای ارائه، موارد زیادی را در خود جای داده است.
مستندات جامع باعث شده تا با تسلط بر قابلیتهای آن، سریعاً به سمت پیشرفت حرکت کنید.
پس آن را امتحان کنید و ببینید که چگونه میتواند پروژههای یادگیری ماشین را ارتقا دهد.
1-1# مفاهیم اولیه sci-kit learn
برای استفاده از sci-kit learn، ابتدا بهتر است با برخی از اصطلاحات که معمولاً در پروژه های یادگیری ماشین به کار میرود، آشنا شوید:
- دقت: نسبت کسری از پیش بینیهایی که یک مدل طبقه بندی به درستی انجام داده است و عبارت اند از:
- در طبقه بندی چند کلاسه، دقت برابر است با تقسیم تعداد کل نمونهها بر پیش بینیهای صحیح
- در طبقه بندی باینری، دقت برابر است با تقسیم تعداد کل مثالها بر مجموع مثبتهای واقعی به علاوه منفیهای واقعی
- دادههای نمونه: نمونه یا ویژگی خاص هر داده، که به صورت x تعریف میشوند. دو دسته از نمونه داده وجود دارد که عبارت اند از:
- دادههای برچسب گذاری شده: شامل دو ویژگی و برچسب است که به صورت (x , y) : تعریف میشوند.
- دادههای بدون برچسب: شامل ویژگی هستند؛ اما برچسب ندارند و به صورت (x , ?) : تعریف میشوند.
- ویژگی: یک متغیر ورودی است که یک ویژگی آن قابل اندازه گیری است.
در هر پروژه ماشین لرنینگ یک یا چند ویژگی وجود دارد. - خوشه بندی: تکنیکی است که نقاط داده را بر اساس شباهتهای موجود بین آنها، گروه بندی میکند.
هر گروه یک Cluster نامیده میشود. - K-Mean Clustering: یک تکنیک یادگیری بدون نظارت است که به دنبال تعداد ثابت K در میانگین نقاط داده است و آنها را به نزدیک ترین خوشه اختصاص خواهد داد.
- مدل: رابطه بین ویژگی و برچسب را تعریف میکند.
- رگرسیون در مقابل طبقه بندی: هر دو مدلهایی هستند که به کاربر این امکان را میدهند که پیش بینیهایی را انجام دهد که به سؤالات مورد نظر وی پاسخ دهد.
به عنوان مثال، کدام تیم در یک رویداد ورزشی خاص برنده خواهد شد:- مدلهای رگرسیون: یک مقدار عددی یا پیوسته را ارائه میدهند.
- مدلهای طبقه بندی: یک مقدار مقوله ای یا گسسته را ارائه میدهند.
2-1# قابلیت های کتابخانه sci-kit learn
قابلیتهایی که کتابخانه sci-kit learn ارائه میدهد، عبارت اند از:
- رگرسیون: از جمله رگرسیون خطی و لجستیک
- طبقه بندی
- خوشه بندی: از جمله K – Means
- انتخاب و ارزیابی مدل
- تکنیک کاهش ابعاد
- پیش پردازش: از جمله نرمال سازی حداقل و حداکثر
2# کاربرد کتابخانه sci-kit learn

کتابخانه sci-kit learn، فقط یک ابزار ضروری برای دانشمندان داده نیست؛ بلکه یک کتابخانه نیروگاهی است که سبب نوآوری در صنایع مختلف میشود.
از مراقبتهای مالی و بهداشتی گرفته تا بازاریابی و تحقیق، سازمانها به دنبال بهرهبرداری از قدرت sci-kit learn برای ساخت راهحلهای یادگیری ماشینی پیشرفته هستند.
برخی از کاربردهای کتابخانه sci-kit learn در دنیای واقعی به صورت زیر هستند:
1-2# تحول در مراقبتهای بهداشتی با کشف سریع تر دارو
استفاده از الگوریتمهای sci-kit learn در صنعت مراقبتهای بهداشتی، سبب انقلابی بزرگ در کشف دارو شده است.
یادگیری ماشینی به منظور پیش بینی نحوه تعامل ترکیبات شیمیایی با پروتئینهای هدف، سبب شده تا سازمانهایی همانند Atomwise بیشتر از همیشه به شناسایی سریعتر تمامی گزینههای دارویی، امیدوار شوند.
این سرعت در روند شناسایی داروها سبب رسیدگی سریع تر به درمان بیماران و کاهش هزینههای تحقیق و توسعه دارویی شده است.
2-2# افزایش سرعت در کشف تقلب در امور مالی
کتابخانه sci-kit learn، به یکی از ابزارهای مهم و حیاتی در امر مبارزه با تقلب، تبدیل شده است.
سازمانهایی همانند JPMorgan از sci-kit learn به منظور تجزیه و تحلیل حجم وسیعی از دادههای تراکنش و شناسایی الگوریتمهای قدرتمند در الگوهای غیرعادی استفاده میکنند که میتواند، نشان دهنده فعالیت متقلبانه آنها باشد.
این نوع مؤسسات با کشف هر چه سریع تر کلاهبرداریهای صورت گرفته میتوانند، میزان ضرر و زیان را تا حد زیادی کاهش دهند و اعتماد مشتری را حفظ کنند.
3-2# تقویت بازاریابی شخصی
کتابخانه sci-kit learn، همچنین با فعال کردن تجربیات شخصی مشتریان، دنیای بازاریابی را متحول کرده است.
سازمانهایی همانند Spotify و Booking.com از کتابخانه sci-kit learn به منظور ساخت موتورهای نظریهای پیچیدهای استفاده میکنند که متناسب با ترجیحات هر کاربر، محصولات یا محتوایی متناسب با آنها را ارائه میدهد.
بازاریابان نیز از کتابخانه sci-kit learn به منظور تقسیم بندی مشتریان و مدلسازی پیش بینی کننده استفاده میکنند تا بتوانند پیام مناسب را در زمان مناسب به مخاطبان ارائه دهند.
4-2# تسریع تحقیقات علمی
کتابخانه sci-kit learn در قلمروی تحقیقات علمی به شکستن مرزها و انجام اکتشافات پیشگامانه و جدید کمک میکند.
sci-kit learn به منظور تجزیه و تحلیل مجموعه ای از دادههای پیچیده در فیزیک و نجوم گرفته تا پیش بینی در زمینههایی همچون ژنومیک و علوم اعصاب کمک میکند و محققان به منظور استخراج بینش و هدایت نوآوری به ابزارهای همه کاره sci-kit learn تکیه میکنند.
با ساده سازی جریانهای کاری تجزیه و تحلیل دادهها، کتابخانه sci-kit learn به دانشمندان کمک میکند تا بر آنچه که به بهترین شکل ممکن انجام میدهند، تمرکز کنند که عبارت اند از پرسیدن سؤالات مهم و کشف دانش جدید.
مواردی که گفته شد تنها چند نمونه از کاربردهای sci-kit learn در دنیای واقعی و در صنایع مختلف بود.
از آنجایی که سازمانهای بیشتری در حال یادگیری ماشینی هستند و به قدرت آن پی بردهاند، بدون شک یادگیری sci-kit learn نقش مهمی در شکل دهی آینده نوآوری مبتنی بر دادهها خواهد داشت.
3# علل اهمیت کتابخانه sci-kit learn

از جمله علل اهمیت کتابخانه sci-kit learn میتوان به طیف گسترده ای از الگوریتمها برای برنامههای مختلف یادگیری ماشین اشاره کرد و همانگونه که در بخشهای قبلی گفته شد عبارت اند از:
- طبقه بندی
- خوشه بندی
- رگرسیون
- کاهش ابعاد
- انتخاب مدل
کتابخانه sci-kit learn، کاربر را به ابزارهایی به منظور هدایت نوآوری در صنایع مجهز میکند؛ اما شاید مهمتر از همه این موارد، تسلط کاربر بر این کتابخانهها است که میتواند مدلهای یادگیری ماشینی قدرتمندی را به منظور حل مشکلات در دنیای واقعی و پیشرفتهای حرفهای در علم داده بسازد.
4# نحوه نصب کتابخانه sci-kit learn
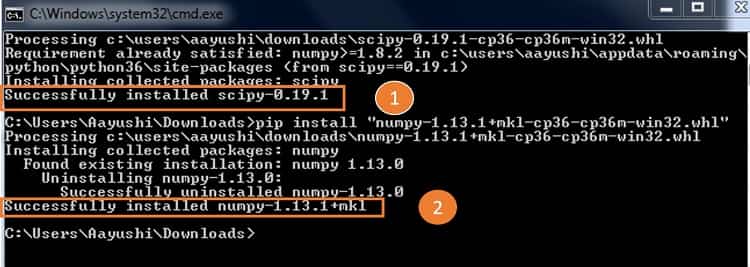
مراحل نصب کتابخانه sci-kit learn در سیستم عامل ویندوز به صورت زیر است:
- پایتون را نصب کنید. سپس، ترمینال را با جستجوی cmd باز کنید.
در خط فرمان نسخه پایتون را وارد کنید. - در این مرحله NumPy را نصب کرده و سپس آن را اجرا کنید.
- سپس نصب کننده یا SciPy Installer را نصب کنید.
- در این مرحله Pip را با تایپ عبارت Python get –py در خط فرمان نصب کنید.
- در آخرین مرحله با تایپ عبارت pip install scikit learn در خط فرمان sci-kit learn را نصب کنید.
5# مزایا و معایب استفاده از کتابخانه sci-kit learn

مزایا و معایب استفاده از کتابخانه sci-kit learn به صورت زیر هستند.
1-5# مزایا
کتابخانه sci-kit learn در هسته خود، مجموعه ای از ابزار قدرتمند و بصری را ارائه میدهد که همه چیز را از آماده سازی دادهها گرفته تا ارزیابی و آموزش مدلها مدیریت خواهد کرد.
در این بخش نگاهی دقیق به مزایای استفاده از این کتابخانه خواهیم کرد.
1) جعبه ای مدولار و انعطاف پذیر
یکی از مزایای مهم در کتابخانه sci-kit learn انعطاف پذیر بودن آن و همچنین نحوه طراحی آن به صورت ماژولار است؛ به این معنا که از بلوکهای ساختمانی مختلفی تشکیل شده که میتوان به صورت مستقل از آنها استفاده کرد یا آنها را همانند لگو به یکدیگر چسباند.
این بلوکهای ساختمانی شامل ابزارهایی هستند که در موارد زیر به کار گرفته میشوند:
- پیش پردازش دادهها
- طیف گسترده ای از برآوردگرها به منظور آموزش مدلهای یادگیری ماشینی
- ارزیابی عملکرد مدلها
این نوع طراحی مدولار به توسعه دهندگان این امکان را خواهد داد که راه حلهای یادگیری ماشین را به صورت سفارشی درآورند.
2) گردش کار آزمایش شده و دقیق
یکی دیگر از مزایای کتابخانه sci-kit learn، این است که گردش کار استاندارد را فراهم میکند؛ چه در حال ساخت یک فیلتر یا یک طبقه بندی کننده تصویر باشید، مراحل اولیه یکسانی را دنبال خواهید کرد که عبارت اند از:
- دادههای خود را بارگیری کنید.
- آن را از قبل پردازش کنید تا برای تجزیه و تحلیل آماده شوند.
- مدل یادگیری ماشینی خود را آموزش دهید.
- نتایج را ارزیابی کنید تا ببینید مدل شما تا چه حد خوب عمل خواهد کرد.
وجود یک فرآیند منسجم همانند آنچه در کتابخانه sci-kit learn است، بسیار مفید است، به خصوص زمانی که شما تازه کار هستید و به تازگی شروع به یادگیری ماشین کردهاید.
3) ادغام با سایر کتابخانههای کلیدی پایتون
sci-kit learn برای ادغام یکپارچه با سایر کتابخانههای کلیدی پایتون همانند Pandas و NumPy طراحی شده است.
این یک مزیت بزرگ برای این کتابخانه است؛ زیرا به این معنا است که میتوانید از نقاط قوت آن کتابخانهها برای تجزیه و تحلیل و ساماندهی دادههای خود به صورتی کارآمد استفاده کنید.
این موضوع درست همانند این است که یک تیم از ابَر قهرمانان علم داده با یکدیگر کار کنند.
4) قابل استفاده در دنیای واقعی
کتابخانه sci-kit learn یک اسباب بازی برای سر هم کردن موارد نیست؛ بلکه یک ابزار جدی است که برای حل مشکلات در دنیای واقعی طراحی شده است.
به عنوان مثال، میتوان از این کتابخانه به منظور ایجاد سیستمی استفاده کرد که به صورت اتوماتیک، ایمیلهای اسپم (Spam) را فیلتر میکند.
در برخی از موارد نیز میتوان با استفاده از این کتابخانه، برنامه ای ایجاد کرد که قادر است به یک تصویر نگاه کند و اشیا موجود در آن تصویر را شناسایی کند؛ همانند ماشینها، درختان یا ساختمانها.
با استفاده از این کتابخانه، امکانات زیادی در اختیار کاربران قرار خواهد گرفت.
5) قابل دسترس برای همگان
یکی از بهترین مزایای کتابخانه sci-kit learn، این است که تیم سازنده آن به سختی کار میکند تا بتواند آن را در اختیار همگان قرار دهد.
چه یک فرد مبتدی و تازه کار برای یادگیری ماشین باشید، چه حرفه ای و سینیور، وجود APIهای مستند و مجموعه ای گسترده از آموزشها شما را هیجان زده خواهد کرد.
با وجود طیف گسترده ای از الگوریتمها که همه چیز را از طبقه بندی گرفته تا کاهش ابعاد، پوشش میدهد، این کتابخانه فوق العاده توانسته، طیف وسیعی از ابزارها به منظور کار کردن و یادگیری ماشین را در اختیار کاربران قرار دهد.
این کتابخانه با توجه به امکاناتی که دارد، اولین ایستگاه برای یادگیری ماشین در پایتون خواهد بود.
2-5# چالشها
قبل استفاده از کتابخانه sci-kit learn، بهتر است با چالشها، محدودیتها و ملاحظات اخلاقی مربوط به استفاده از آن آشنا شوید.
در حالی که این ابزار به صورت غیرقابل انکاری قدرتمند است؛ اما دارای معایب قابل توجهی است که هر دانشمند داده باید از آن آگاه باشد.
از نظر فنی sci-kit learn به دلایل زیر با چالشهایی مواجه است:
- پشتیبانی محدودی برای وظایف یادگیری عمیق
- مشکل در مدیریت مؤثر دادهها با ابعاد بالا
- مشکلات مقیاس پذیری هنگام کار با مجموعه ای از دادههای بسیار بزرگ
- ادغام دست و پا گیر با برخی از ابزارهای صنعتی
این محدودیتها میتوانند بر عملکرد کارهای پیچیده ای همانند تشخیص تصویر یا پردازش زبان طبیعی تأثیر بگذارند و اغلب به تکنیکهای پیشرفته تری نیز نیاز خواهند داشت.
همچنین ممکن است، مدلها به منظور مقیاس بندی کارآمد در محیطهای کلان داده با مشکل مواجه شوند.
با این حال، پیامدهای اخلاقی استفاده از sci-kit learn شاید حتی مهم تر از این موارد باشد.
یکی از نگرانیهای اصلی پتانسیل سوگیری الگوریتمی در مدلهای ایجاد شده با این کتابخانه است.
اگر این الگوریتمها به دقت مدیریت نشود، این سوگیریها میتوانند منجر به ایجاد نتایج ناعادلانه یا تبعیض آمیز، به ویژه در حوزههای حساسی همانند مراقبتهای بهداشتی شوند.
بیمارستانی را تصور کنید که از مدلی برای پیشبینی سطوح خطر در بیمار استفاده میکند.
اگر آن مدل روی دادههایی آموزش داده شود که اطلاعات جمعیتی خاصی را کمتر از میزان واقعی نشان دهد، ممکن است به صورت سیستماتیک، میزان خطر را برای آن گروه دست کم بگیرد و سبب شود تا مراقبتهای کافی انجام نشود.
جامعه دانشآموزان نیز با مسئله تعصب و انصاف دست و پنجه نرم میکنند؛ اما هیچ پاسخ آسانی برای آن وجود ندارد.
تلاشها برای تفسیرپذیرتر و شفاف تر کردن مدلها به منظور کاهش این خطرات و اطمینان از پاسخ گویی آنها بسیار مهم خواهد بود.
6# چشم انداز آینده برای کتابخانه sci-kit learn

چشم انداز آینده برای کتابخانه sci-kit learn به صورت زیر خواهد بود:
1-6# افزایش مقیاس و ادغام یکپارچه
با رشد حجم دادهها، انتظار میرود نسخههای آینده sci-kit learn، مقیاس پذیری بیشتری را ارائه دهند.
این امر به سازمانها کمک خواهد کرد تا به صورت مؤثرتری مجموعه ای از دادههای بزرگ را مدیریت کنند.
علاوه بر این، ادغام یکپارچه تر با کتابخانههای یادگیری عمیق، در همین راستا خواهد بود.
از جمله مزیتهای ادغام پیشرفته میتوان به ایجاد ساده تر مدلهای هوش مصنوعی پیشرفته اشاره کرد که از تکنیکهای کلاسیک یادگیری ماشین و رویکرد یادگیری عمیق پیشرفته استفاده میکنند.
2-6# بهبود قابلیت تفسیر مدل
با استفاده هر چه بیشتر از مدلهای یادگیری ماشین در کسب و کارها، تقاضا برای شفاف سازی افزایش مییابد و احتمالاً بر توسعه ابزارهای مفیدتر به منظور تفسیر پذیری مدل، تمرکز خواهد کرد.
این امر به دانشمندان کمک خواهد کرد تا مدلهای خود را اصلاح کنند و صنایع را قادر خواهد ساخت تا از مقرراتی پیروی کنند که به هوش مصنوعی قابل توضیح نیاز دارند.
3-6# تولید دادههای مصنوعی
گسترش sci-kit learn به تکنیکهای هوش مصنوعی مولد میتواند، نحوه رویکرد کسب و کارها به سنتز و تقویت دادهها را متحول کند.
با تولید دادههای مصنوعی، سازمانها میتوانند آموزش مدل را بدون نیاز به خطر انداختن حریم خصوصی یا امنیت ارتقا دهند.
این امر نیاز به جمع آوری گسترده داده در دنیای واقعی را کاهش میدهد که میتواند سبب کاهش هزینهها و سرعت بخشیدن به توسعه راه حلهای هوش مصنوعی قوی شود.
 |
درباره نویسنده : فریبا صالح
نظرتون درباره این مقاله چیه؟
ما رو راهنمایی کنید تا اون رو کامل تر کنیم و نواقصش رو رفع کنیم.
توی بخش دیدگاه ها منتظر پیشنهادهای فوق العاده شما هستیم.
